
Bron
Hoi!
Ik ben Daan! Ik denk dat de SEO-discipline een op onderzoek gebaseerde discipline is. Een van mijn favoriete concepten is Garbage In, Garbage Out (GIGO) , waar ik eerder naar ga linken dan uitleggen, maar ik verwacht nog steeds dat je het leest! Aangezien slechte gegevens slecht onderzoek voortbrengen, slechte tactieken voortbrengen, denk ik dat het belangrijk is om intellectueel eerlijk en valide onderzoek te hebben. Als onze branche maar open stond voor peer review. Voor degenen die geïnteresseerd zijn in peer review van ander onderzoek, dit kostte me ~60 minuten all-in.
Vandaag ga ik deze studie van Ryan Jones en Sapient Nitro op Twitter door vakgenoten beoordelen en wat tegengesteld, tegenstrijdig en beter onderzoek aanbieden.
Achtergrond
Hier is de studie die ik ga bespreken en ik ga gewoon eerlijk zijn, het is problematisch onderzoek en dit is waarom.
- Het hield zich niet bezig met basisgegevensverwerking, zoals het verwijderen van stopwoorden en andere veelvoorkomende woorden. Dit betekent dat de meest voorkomende spraakfragmenten in het onderzoek naar boven komen, niet inzichten uit trefwoordkeuzes. Hoewel er later werd beweerd dat de stopwoorden het punt waren, begrijp ik eerlijk gezegd niet waarom dat ooit het geval zou zijn, en zonder meer inspanning van de auteurs hier denk ik niet dat dit een goede rechtvaardiging is. Voor themaclassificatie zijn stopwoorden nutteloos . Hoe dan ook, hier bij LSG gebruiken we de NLTK-bibliotheek om onze gegevens voor te verwerken en het verwijderen van stop en andere veelvoorkomende woorden is een basistoepassing van die bibliotheek. Zonder de juiste verwerking en opschoning van de data is geen enkel inzicht waardevol, onthoud GIGO.
- De dataset. BrightEdge heeft geen erg goede dataset en ze zijn niet erg transparant over hoe ze die krijgen. Eerlijk gezegd zou ik de hele dag kritiek kunnen hebben op hun platform en serviceaanbod, maar dat is niet ter zake. Als u een trefwoordenset gaat analyseren die op zijn best representatief zal zijn (150k trefwoorden is niets in het trefwoordencorpus van alle zoekopdrachten), dan moet u ervoor zorgen dat deze een zo nauwkeurig mogelijke weergave van de werkelijke gegevens is. Dus als BrightEdge een minder representatief trefwoordencorpus heeft dan bijvoorbeeld AHREF's, dan zou dat weer betekenen dat de inzichten niet te vertrouwen zijn, alweer GIGO.
Gelukkig weten we hier bij LSG hoe we dingen zoals stopwoorden en andere veelvoorkomende delen van schrijven kunnen verwijderen bij het verwerken van grote hoeveelheden gegevens, en ik heb kunnen krijgen wat volgens mij een betere trefwoordenset is om in het onderzoek te gebruiken. En zoals je zult zien als ik je hier doorheen loop en je de output ziet, is het gewoon veel bruikbaarder.
Het onderzoek
Ik kreeg de top 100k-zoekwoorden in volume van AHREF's dankzij de geweldige Patrick Stox nadat ik deze tweet van AHREF's CMO had gezien en geïntrigeerd was:
Snelle SEO-tip:
Een lege zoekopdracht in @ahrefs Keywords Explorer geeft u toegang tot onze VOLLEDIGE ~4 miljard Amerikaanse trefwoordendatabase (de grootste van de branche trouwens )!
Gebruik vervolgens S. volume-, KD- en Word-telfilters om "hi-vol, low-comp" -query's te vinden.
Perfect om nieuwe kansen te ontdekken!
pic.twitter.com/BGfrlxQ45s
— Tim Soulo (@timsoulo) 4 augustus 2021
 pic.twitter.com/BGfrlxQ45s
pic.twitter.com/BGfrlxQ45sHet proces:
Ik nam de lijst met de beste 100.000 zoekwoorden per volume en verwerkte de ngrammen als volgt:
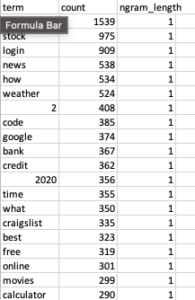
Toen nam ik de resultaten (die er zo uitzien)
en heb ze door de word cloud creator op wordart.com gehaald . Dit is mijn favoriete maker van woordwolken omdat het gewoon een geweldig snel gegevensproces doet. Je kunt veelvoorkomende woorden verwijderen, stammen gebruiken om nauwe variaties op te rollen en te spelen met het visuele ontwerp. 10/10, zeer aan te bevelen.
En voor degenen die 100.000 trefwoorden willen argumenteren versus 150.000 trefwoorden; deze tabel zal je hopelijk laten zien dat het niet super relevant is in termen van wiens waterdruppel groter is.:

De resultaten
Er moet echte informatie worden verzameld zodra u veelvoorkomende woorden zoals 'voor' uit de analyse verwijdert. bekijken!

Spoilers, als je de juiste data-analyse op data uitvoert, kun je echte inzichten naar boven halen! De meest voor de hand liggende is die #1 gram, "bijna".
Luister, ik zeg al een tijdje dat alle zoekopdrachten lokaal zoeken zijn. AJ Kohn zegt het al een tijdje. Dit komt omdat het de realiteit van de situatie is. Lokalisatie van zoekresultaten is de #1 trend die SEO's missen. In de eerste plaats omdat lokaal zoeken altijd is neergekeken als dit rare ding dat MKB's doen. Hun verlies is onze winst denk ik
Een ander heel interessant ding is "vs". Vergelijkingsquery's zijn erg populair en u zou ze in uw inhoud moeten gebruiken als ze zinvol zijn. De mensen die op zoek zijn, zijn dat al!
Daarnaast zijn er enkele andere inzichten die ik basis, maar goede validatie zou noemen. Navigatievragen zijn erg hoog, mensen houden van gratis spullen en stonks enz.
Hoe dan ook, hier zijn de ngram-gegevens van het onderzoek voor degenen die het zelf willen onderzoeken. Aarzel niet om vervolgonderzoek te posten, zorg er wel voor dat u ons die link geeft. Ik ga de top 100k AHREF-gegevens niet delen, omdat jullie allemaal weten waar je heen moet als je het wilt kopen
Het bericht Dan Peer-recensies Wat onderzoek: topzoekwoorden op volume verscheen eerst op Lokale SEO-gids .
